Analyze what ChatGPT users are asking using your website's bot traffic
Tutorials & How-To Guides

This post shows you how to analyze bot visits in your server logs to understand what topics real ChatGPT users are interested in, without relying on unreliable third-party prompt volume data. We’ll cover how to extract, categorize, and turn this traffic into actionable insights for AI content optimization.
The blackbox of AI visibility tracking
The new world of AI search optimization (AEO, GEO, etc) can be a bit of a blackbox compared to traditional SEO. Prompts are not the same as keywords. Rather than 3-4 word terms, users are now writing longer, more customized prompts to find products and services.
Unlike Google keywords, prompts from ChatGPT and others are largely a closed ecosystem. Data providers offering "prompt volumes" should be looked at with a healthy degree of skepticism. Most data from third parties is collected via browser extensions and is heavily downsampled, losing breadth of coverage. Or it's from ChatGPT app clones whose audience differs significantly from real ChatGPT users.
Not having prompt volume makes tracking AI citations and mentions likely subject to selection bias. Do we really know that the prompts we picked to track are representative in breadth and volume of what users are actually interested in? For example, if the prompts we select skew towards our product's strengths, then we will inevitably over-represent our AI visibility.
Even with a robust (200-500) and representative set of prompts, we are likely still missing some topical areas that might be surfacing you or your competitors. So how do we take out the guesswork? It turns out we can use real website visits from ChatGPT's agents and bots to determine what users are searching for.
What you'll need
- A website or blog with 50+ pages/articles
- Access to server log files
- Basic spreadsheet skills
- General familiarity with using LLMs
Background: What are AI bots and server logs?
Similar to Google's Googlebot search index crawler, all AI chatbot companies have similar bots that scour the web to gather data for LLM training, construct search indexes, or visit websites in real-time on behalf of their users. Check out Open AI’s crawler info page and read our intro analysis of AI bots here.
The key difference is that unlike Googlebot, most AI bots do not run Javascript, can only be measured server-side, and won't show up in most product analytics tools like Google Analytics or Amplitude. Side note: if you want these bots to find your content and learn about your brand, make sure your site is server-side rendered and not overly reliant on Javascript (find a how-to guide here).
While not measurable from the client-side, these bots and crawlers are traceable from server logs. You can find your server logs in the edge services you use to host your website (e.g. Vercel), CDNs (e.g. Akamai), or services that protect from malicious bots (e.g. Cloudflare).
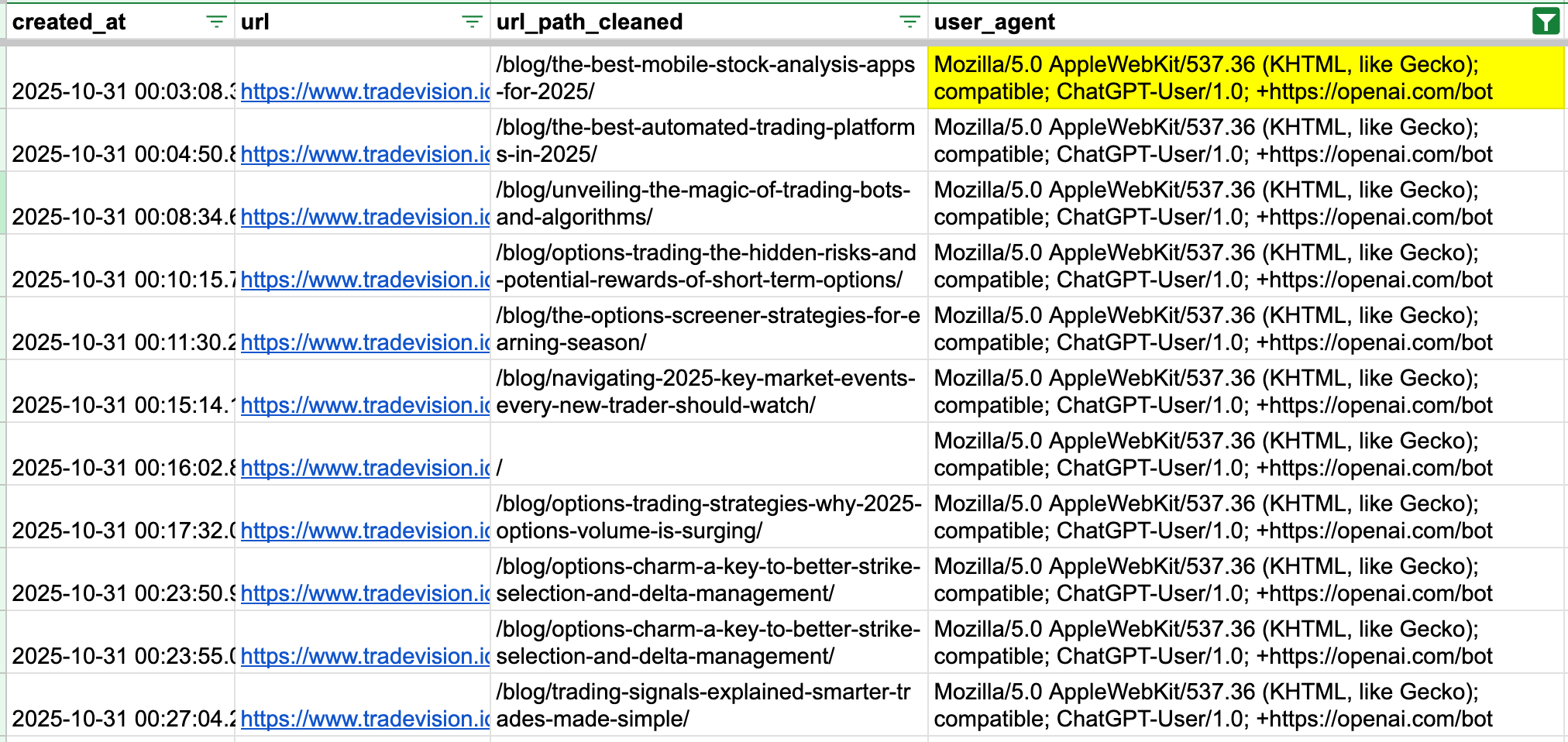
An example server log looks like this:
185.72.144.53 yourwebsite.com - [12/Feb/2025:14:32:09 +0000]
"GET /features/our-brand-new-awesome-feature HTTP/1.0" 200 64312 "-"
"Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/97.0.4692.71 Mobile Safari/537.36
(compatible; Googlebot/2.1; +http://www.google.com/bot.html)"ChatGPT-User bot: the signal in the noise
Unlike LLM training bots that crawl websites indiscriminately to gather training data, the ChatGPT-User bot is special. According to OpenAI's documentation, this bot triggers "when users ask ChatGPT a question" that requires real-time information from your site. This means every visit from ChatGPT-User represents an actual user prompt happening in ChatGPT.
Steps
For this example we'll use Tradevision.io, an AI data platform for options trading.
1. Extract and Clean Log Files
- Take log files from at least a week, ideally a month
- Filter only for response codes 200 (success) and 304 (when the server tells the bot to use a cached version)
- Normalize URLs: remove UTM parameters, strip off domain and subdirectories
- Filter only for user agent strings that contain
ChatGPT-User
2. Categorize/Cluster Your Pages
Quick and dirty: LLM-only approach
- Take the path and ask ChatGPT to assign a non-generic content topic. For example,
/blog/the-best-mobile-stock-analysis-apps-for-2025/might get the topic "Stock Analysis Apps." - Take another page and ask the LLM to first evaluate if the page fits nicely into any existing topic categories (if so, assign it). If not, create a new topic category. Example prompt:
Given these existing topic categories: [list categories]
For this URL path: [path]
Either assign it to an existing category or create a new non-generic topic category.Better: Vector embeddings and clustering
- Clean each path string and send it to a vector embeddings model such as OpenAI's Vector embeddings API. You can also pass in meta descriptions or page titles to provide more context about the page (or if your path names don't accurately represent the page topics... tisk tisk).
- Store each vector matrix and use K-means clustering to group the pages into groups. As a rule of thumb, aim for 15-30 groups depending on how many pages you have. Assign each group a cluster_id.
- Send the list of cleaned paths to an LLM asking for a non-generic content topic that represents all pages in each cluster.

3. Aggregate Visits and Analyze
- Now that you have labeled clusters of pages, you can sum up all visits from the
ChatGPT-Userbot. Also count the number of pages per cluster. - Once you have the results, look at which topical areas receive the most visits from the
ChatGPT-Userbot as a proxy for what real users are prompting ChatGPT. In most contexts, we'd recommend looking at Visits/Page to normalize for topics where there is a high number of existing pages. - Bonus: Pull in your GA4 or other attribution data filtered for referred human users from ChatGPT for these pages. Adding user traffic from ChatGPT divided by the number of
ChatGPT-Userbot visits can serve as a rough CTR.

What Actions Can You Take From This Data?
Identify top topical areas for ChatGPT users:
- Create more content in this area if applicable
- Ensure that content is up to date and structured in an LLM-friendly way: digestible, answers questions directly, cites sources and data
High ChatGPT bot traffic but low human visitors (low CTR):
- Content is referenced by ChatGPT, but users have low need to click through and visit the site
- Restructure content to be more action-oriented and compelling
High human visitors but low ChatGPT bot traffic:
Are there technical blockers hindering bots from accessing the page?
- Does it require Javascript to access or is it not server-side rendered?
- Are AI bots restricted in robots.txt or by bot blocking in proxy servers like Cloudflare?
- Is content location-restricted, loading too slow, or too lengthy?
Interested in these findings but don't have access to log file data or just seems like a lot of work?
Good news! At GPTrends we’ve been working a 100% free Agent Analytics feature to help you understand how AI agents and bots crawl, reference, and interact with their content, turning AI visibility optimization from a black box into data-driven actions.
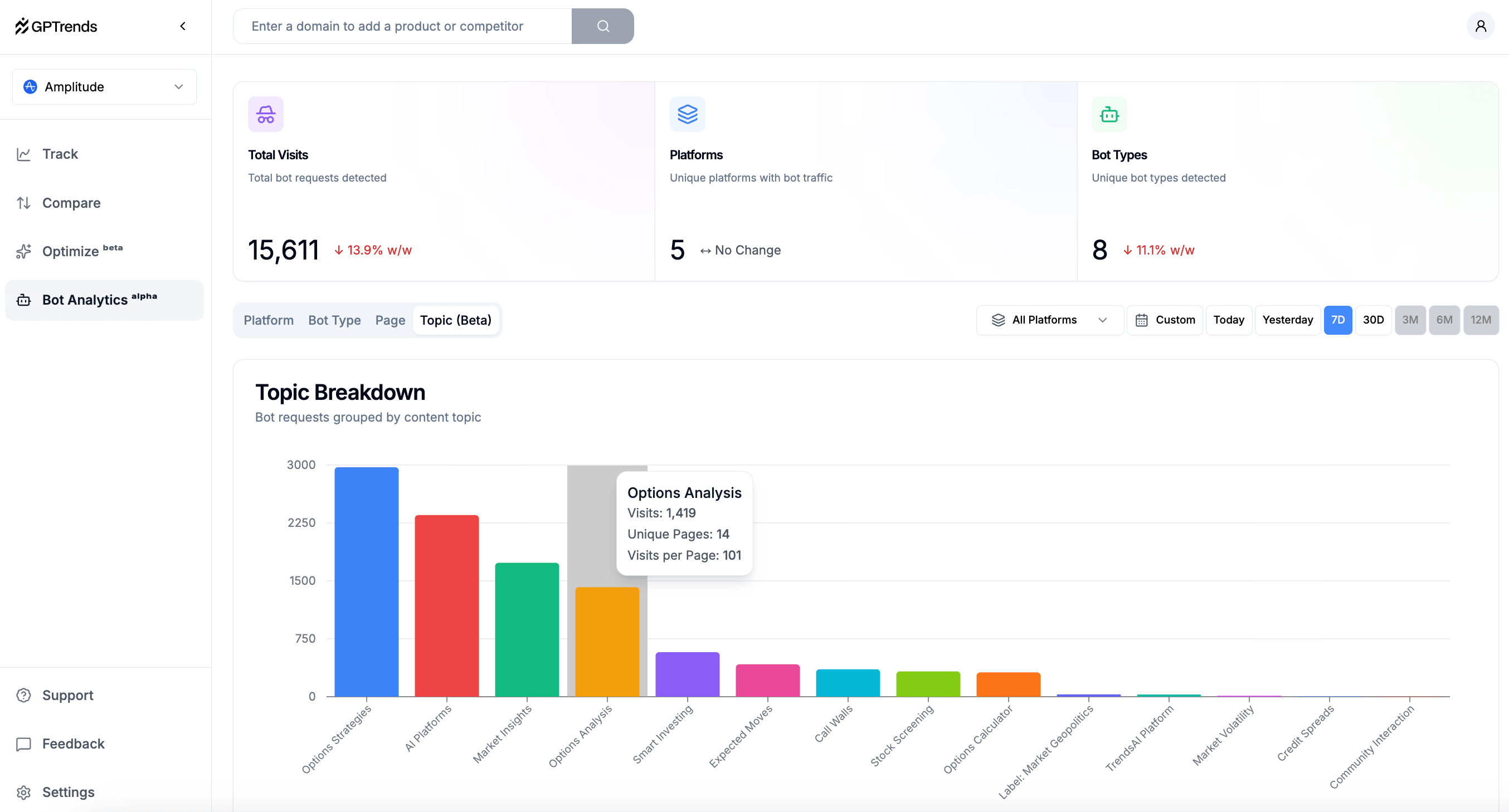
P.S. It looks nicer than a spreadsheet too. Sign up for GPTrends to check it out yourself.




