The Variability of AI Search
Data Analysis
This week we took a look into the variance of product recommendations on ChatGPT its impact on AIO strategy.
How do AI Search results differ from Google? 🕵🏻♂️
For one thing, they’re much more variable. The same prompt from the same user can produce greatly different results.
Unlike traditional search results in Google, results produced by LLMs in products like ChatGPT, Perplexity, Claud and others are non-deterministic. This means that the old way of understanding SERP results by location and language won’t cut it. For product visibility analysis in AI Search, we need to run prompts multiple times and analyze the distribution of results.
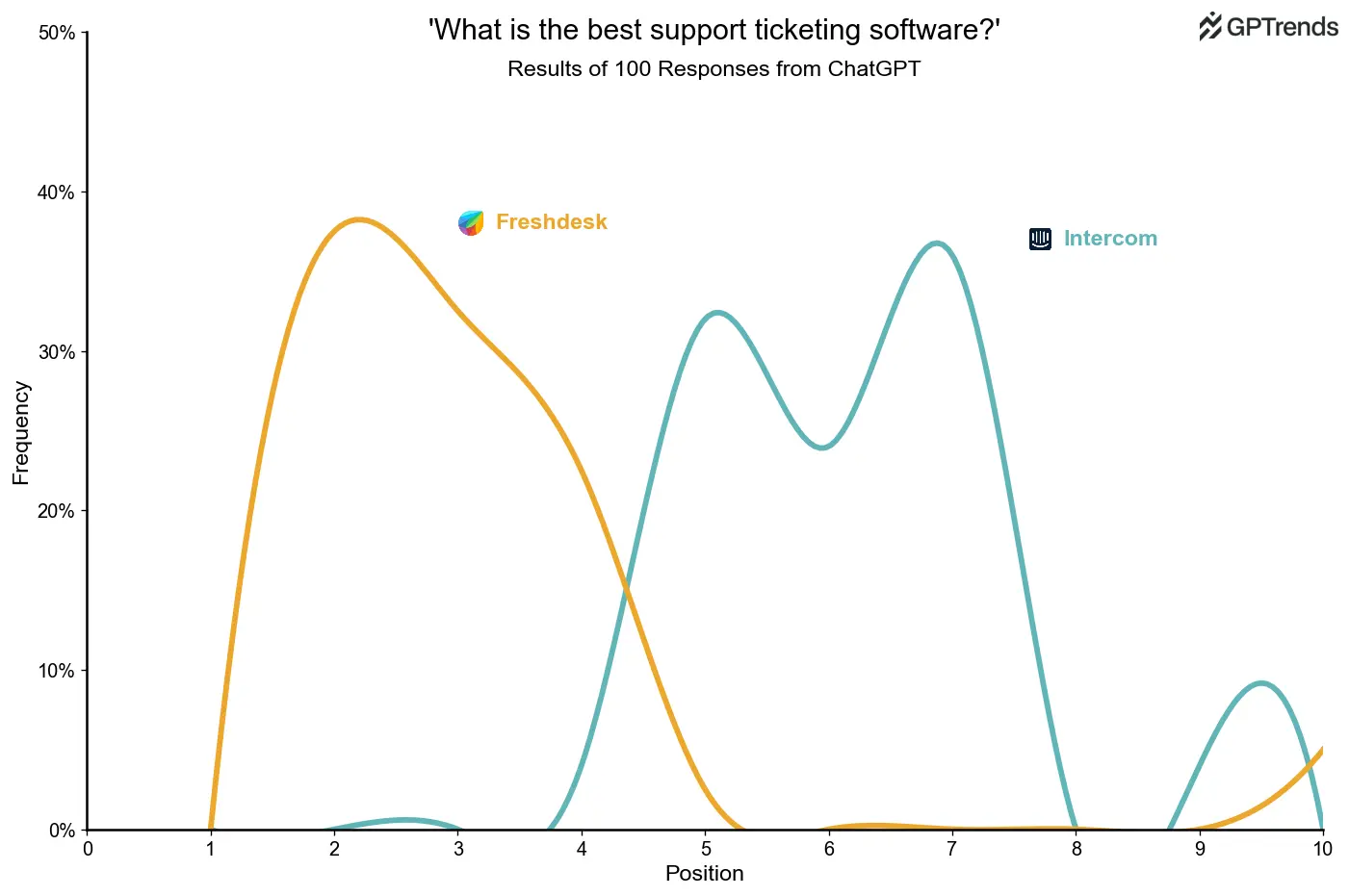
For example, let's take a look at a common search for support software: "What is the best support ticketing software?" We ran this with ChatGPT 100x and analyzed which products are recommended:
- Zendesk: appears 94%, avg. rank 2.0
- Freshworks: appears 80%, avg. rank: 3.3
- Zoho: appears 76%, avg. rank: 3.9
- Intercom: appears 50%, avg, rank 6.1
We can see the top category products are only mentioned in 80-90% of the results and their ranking varies significantly. For most result sets, ChatGPT recommends 3-5 products, so ranking high is crucial for visibility.
What does this all mean? 🤔
Much of this variability is due to the way LLMs "think" — they use a neural network to predict the next word in a sequence, which can lead to varying results. The variability also depends on whether the prompt triggers an external search query or relies solely on the model's training dataset.
What does this mean for SEO and AIO visibility? For one, it creates more opportunity for "little guys" — if you used to be buried on the 2nd page in the Google world, you have a higher chance of getting surfaced by AI systems, at least part of the time. Strategically, this means brands need to rethink how they optimize for discovery, focusing less on traditional SEO tactics and more on comprehensive, authoritative content that AI systems recognize as valuable.
Discover more



